We now have all sorts of platforms that can test seemingly innumerable combinations of patterns, indicators, trade management rules, markets, and time frames. We have seen systems work on 60-minute bars, but fail completely on 120-minute bars. Popular candlestick patterns are aggressively used to generate systems that pass whatever gauntlet has been defined as “robust.”
The no-coding-required algo generators only look at the metrics. If a system looks great on a 445-minute chart using a HAMMER or HANGING MAN candlestick pattern, and it passes the out-of-sample inline stress testing, then it becomes one of the noodles that sticks to the wall.
I am not being critical of this overall approach. Expanding the search universe by using a wide spectrum of multi-minute bars is somewhat newer, and in many ways, somewhat novel. Back in the day, we mostly stuck with daily bars or common intraday intervals such as 15-, 30-, and 60-minute bars. A 445-minute bar was not even considered. But with today’s tools, almost anything is possible.
What I am critical of is the tendency to take those results at face value without drilling down into the underlying logic. A system that passes a statistical test is not automatically a system that makes sense. And more importantly, it is not automatically a system that can actually be traded.
Enter the Engineer
Plotting the algorithm on the chart and examining the actual trades is Step #1.
Why do this, you may ask? The code is the code. The generator produced an impressive-looking algorithm. The metrics passed the test. The equity curve looked promising.
But what if the algorithm just got lucky? What if it is already drifting away from its foundational premise?
For example, suppose I create a strategy using momentum along with the Hammer and Hanging Man candlestick patterns. The results look promising. A hypothetical generator was fed the available data, churned through the combinations, and produced the following candidate system:
Candidate System
Time Frame: 445-minute bars Market: @ES Buy: Momentum is positive and Hammer pattern occurs Sell Short: Momentum is negative and Hanging Man pattern occurs Risk: $2,800 to make $5,600
From an engineer’s perspective, I kind of like it.
It has several attractive qualities:
It is symmetrical.
It is applied to a good, liquid market.
It uses a different time frame.
It involves time-tested candlestick patterns.
The risk-to-reward ratio is a clean 1-to-2.
But then the engineer asks the next question:
Can the bar interval itself be trusted?
You cannot slice a pie evenly using 30% slices.
Most trading days consist of 23 hours, or:
23 × 60 = 1,380 minutes
Now divide the trading day by the selected bar interval:
1,380 ÷ 445 = 3.10
Or stated another way:
445 + 445 + 445 = 1,335 minutes
That leaves a remainder of:
1,380 – 1,335 = 45 minutes
So, the chart does not really consist of four equal 445-minute bars. It consists of three large 445-minute bars and one small 45-minute bar.
That matters.
A Hammer or Hanging Man pattern detected on a 445-minute bar is not the same thing as a Hammer or Hanging Man pattern detected on a 45-minute cleanup bar at the end of the trading session. The pattern may have the same name, and the code may treat it the same way, but structurally it is not the same event.
This is where generated code becomes engineering work.
The generator saw a metric. The engineer sees a structural problem
Small Piece at the EOD
But Can You Argue With the Numbers?
At this point, someone could reasonably say, “Yes, the final bar is shorter, but look at the performance report.”
And that is a fair objection.
The numbers appear impressive. The system produced a solid net profit, a respectable profit factor, and a reasonable percentage of winning trades. On the surface, the strategy looks like something worth pursuing.
But this is exactly where the engineer has to slow down.
Most candlestick patterns are built around the range, body, open, close, high, and low of the bar. In other words, the pattern is not just a label. It is a structural interpretation of price movement during a specific unit of time.
Here is the EasyLanguage definition of the Hammer and Hanging Man pattern:
if Body < BodyAvg and Body > 0 and BodyLo > MedianPrice and BodyLo - Low > Factor * Body and High - BodyHi < Body
then if Close < PriceAvg then { TREND IS down } oHammer = 1 else if Close > PriceAvg then { TREND IS up } oHangingMan = 1 ;
C_Hammer_HangingMan = 1 ;
Hammer/Hanging Man
The key element here is the current bar’s open-to-close body, along with the relationship of that body to the bar’s total range. That makes perfect sense when each bar represents the same amount of market time.
But do you really want to rely on a bar that always covers only 45 minutes when the other bars cover 445 minutes?
From an engineering standpoint, I do not believe the smaller bar provides enough information to fulfill the spirit of the complete pattern. The code may identify the shape, but the market structure behind that shape is not equivalent.
In this case, it appears that a malformed Hanging Man triggered a short sale. The 45-minute cleanup bar completed the pattern, and the system acted on it.
And yet, the numbers look good.
That is the trap.
A performance report can tell you that something worked historically. It cannot tell you whether the logic that produced those trades was structurally sound. That part still requires inspection, judgment, and engineering.
My goodness!
Do You Throw the Results Out Over a Technicality?
Not necessarily.
This is where engineering judgment comes into play. The fact that one of the trades was triggered by a malformed candlestick pattern does not automatically mean the entire idea is worthless. The performance report may still be pointing toward something useful. The combination of market, time frame, momentum filter, and trade management rules may contain real information.
But it does mean the results should not be accepted at face value.
The first question is not, “Did it make money?”
The first question is, “Did it make money for the reason I think it made money?”
That distinction matters.
If a strategy is supposed to exploit a Hammer or Hanging Man pattern, then the bars used to form those patterns should be structurally comparable. A 45-minute cleanup bar sitting next to three 445-minute bars may satisfy the code definition, but it does not necessarily satisfy the trading premise.
So I would not immediately throw the results away. I would move the candidate system into the engineering phase. That means isolating the questionable condition, removing or correcting the structural flaw, and then testing whether the core idea still holds up.
If the system falls apart after making those changes, then the original result was probably more fragile than it appeared. If the system survives, then you may have something more interesting.
That is the difference between throwing spaghetti against the wall and engineering a tradable system.
The generator found a candidate.
The engineer decides whether that candidate deserves to live.
Next Installment — Working Your Craft: Some Coding Required
Don’t worry — I do the heavy lifting for you.
But there is real value in sitting in front of the editor, debugging the code, flipping system components on and off, and examining the functions that drive the trades. That process is a win-win. Even if you do not grasp every minute detail, that is okay.
You do not have to become a full-time programmer to benefit from this exercise.
Understanding the why behind the code is often enough. Why did the trade trigger? Why did the pattern qualify? Why did the system enter there instead of somewhere else? Why did the performance report look good?
Those questions move you beyond blind acceptance of the results. They turn a generated candidate into something you can inspect, challenge, and eventually trust — or reject.
In the next installment, we will take the same strategy idea and make it more practical for real-time trading. The larger bar can still generate the signal, but the smaller bar can handle the execution. In TradeStation terms, Data2 can define the setup, while Data1 handles the trade.
Watching a system trade on a large bar can hide too much of the story. If a trade enters, gets stopped out, or takes a profit all within the same large bar, the report may tell you what happened, but it does not really show you how the trade unfolded.
That is why I like to watch the trade develop on a smaller execution bar. Seeing the five-minute bar crawl across the screen gives you a much better feel for the trade. You can see the entry, the follow-through, the hesitation, the stop pressure, and the eventual exit in a way that a large bar simply cannot reveal.
Maybe that is just me, but I find it much more satisfying.
And more importantly, it provides a clearer picture of whether the trade was realistically executable.
At Futures Truth, we focused on one thing: walk-forward results across hundreds of trading systems. Back then, the industry was unrecognizable compared to today—if you can even call what exists now an “industry.”
Just this morning, I was reminiscing about vendors who sold strategies for upwards of $5,000. Those packages usually consisted of a set of rules (disclosed or not) and a rudimentary DOS-based program to generate simple charts and next-day orders. This was well before the heyday of TradeStation; those days are gone forever, for better or worse.
Back then, if a system performed well in walk-forward analysis, it earned a ranking. In those days, a Futures Truth ranking meant something. Sometimes, however, that ranking felt like a curse. Critics even argued you could “fade” a top-ranked system and make more money by taking the opposite trade. The reality is that many of those legendary “Top Ten” systems—built for a different era—simply wouldn’t survive in today’s markets.
Side Bar: There are still services such as Striker and The Collective that still monitor trading systems. Striker only shows real execution, which is mostly a good thing – real execution costs are shown. But so is broker error. Heck, we are all human and we all make mistakes. Striker is upfront with this, and they state they will do the best they can – execution can be a beast.
Speaking of execution – The Sunday Evening Gap
A Traders Nightmare. Most likely Trend Followers were short during the huge gap here!
Imagine, having a stop order in crude oil on a Sunday evening when the market opens thousands of dollars through your stop. If a system derived position is short the broker’s only directive is to GET OUT – no matter what, at the first off ramp. The above chart shows a single contract slip on crude futures at the genesis of the Iran War.
The Million-Dollar Question
The second most common question I was asked at Futures Truth was: “How do I know if the system I’m trading is broken?”
Can you guess the most common one? “If it were your money, which system would you trade?”
We never answered that one directly; there was never a simple black-and-white answer. But the second question—the one about “broken” systems—usually surfaced when a trader was deep in a drawdown.
Seasoned traders know that systems ebb and flow; drawdown is simply the “tax” we pay to play the game. Others, however, get “married” to a system and stick with it until “death do us part.” My standard response back then was always:
“Is your current performance still within the boundaries of the backtest?”
In other words, has the system exceeded its historical maximum drawdown by a meaningful margin? Does the current real-time performance look like other “rough patches” in the historical equity curve? If the answer was yes, the trader would usually give it a little more room.
Into Unexplored Waters
Those were simpler days, but the core problem remains: we cannot see the future. No forward analysis can tell you with certainty what a trading system will do next. What it can do is tell you when the system has moved into “unexplored waters.” Once you know that, the decision to stay, abandon, or pause becomes much easier.
All trading systems oscillate between success and failure. If a system has a genuine technical edge, that edge may eventually reassert itself—provided you have the time and capital to wait. But most traders don’t have unlimited resources.
Recently, the market activity surrounding the Iran conflict has pushed many systems into intense drawdowns. The same old questions have reared their heads again. This time, however, I wanted to provide a more empirically derived analysis. I’ve developed a disciplined approach to measuring risk and reward that moves beyond “gut feel.”
To illustrate, I pulled a system off my shelf that I originally designed for retail consumption back in June 2018. Here is how it’s currently holding up:
Hypothetical Results: Before and after development.
The Profit Mirage
This is a mean-reversion approach. I remember thinking back in 2018: How much longer can this bull market continue? With that in mind, I utilized a simple regime filter. After just a few weeks of trading later that year, I genuinely thought the system might be broken. The market spent a large portion of that fall and winter below its 200-day moving average, and shorting simply wasn’t working.
The system then went dormant for a long stretch, finally “waking up” at the height of the pandemic. Had you stuck with it, you would be up significantly today (though we stopped trading right at the onset of the pandemic).
But here is the catch: Profit, by itself, is not enough to determine if a system is broken. As long as they are making money, most traders never bother to peek below the surface. This system would likely be sitting near the top of the Futures Truth rankings today. But let’s dive in and see how it actually performed on its “test of time.”
Test 1 – Baseline Projection
Baseline projection based on in sample average monthly return.
Is Outperformance Always a Good Thing?
Looking at the chart above, you see a steep deviation below the baseline initially, followed by a rocket-ship move to the upside. By late 2025, the actual equity is sitting way above the red dashed expectation line.
Most traders would see this and think they’ve struck gold. “Isn’t this what we want—a strong positive deviation?” they’d ask.
In a world of simple “bottom-line” thinking, the answer is yes. But in the world of professional algorithmic trading, this chart is screaming a different story. To a seasoned developer, deviation is deviation. Whether it’s to the upside or downside, moving this far away from the “expected” path suggests that the strategy’s original statistical model is no longer in control.
When a system starts generating 190% of its expected return, it’s often because it has inadvertently stepped into a high-volatility regime it wasn’t designed to navigate. If the “upside” is this aggressive, you can bet the “downside” risk has scaled right along with it.
Test 2: Monte Carlo Analysis on Walk Forward
Return and Drawdown sitting on the tails.
The Statistical Reality Check
To understand why I called this system “Degraded” despite the profits, we have to look at the Monte Carlo Walk Forward distributions. This is where we compare real-time performance against thousands of simulated “alternate realities” based on the system’s history.
1. The Equity Distribution (The Good News… or is it?)
In the top chart, our actual forward equity of $67,575 (the dashed red line) sits at the 97th percentile.
Interpretation: Out of 1,000 possible outcomes, the system performed better than 970 of them. While this looks great, being this far out on the “tail” of the distribution suggests we are no longer operating in a normal environment.
2. The Drawdown Distribution (The Warning)
The bottom chart is the real story. The actual worst drawdown reached $18,588, placing it in the 98th–99th percentile of severity.
The Comparison: The median expected drawdown was only $8,125.
The Verdict: We have blown past the 90th percentile of $13,611 and are deep into the “danger zone.”
The Bottom Line
When a system hits the 97th percentile for gains but simultaneously hits the 99th percentile for drawdown stress, the math is telling you that the character of the strategy has changed. You aren’t just trading a system in a “rough patch”—you are trading a system that has moved into a risk regime it was never built to survive. This is the “evidence-based framework” I mentioned earlier. Without these charts, you’re just guessing. With them, you have the data to justify stepping aside.
The Verdict: Test 3 – Overall Assessment
This is where the “gut feel” ends and empirical analysis begins. The following commentary is generated by my new software; a quasi-expert system designed to pair raw statistical results with descriptive, actionable interpretation.
Return delivery is running ahead of baseline: expected annual return is 18% versus actual annual return of 34% and expected annual gain of $4,477 compares with actual annual gain of $8,536. However, that stronger return delivery has come with a less stable path and/or materially heavier risk than history would suggest. Risk is materially worse than the historical profile: actual worst drawdown of $18,588 is 2.670 times the historical drawdown of $6,962. Risk conditions are now in the Critical Risk range. The realized monthly path is poorly aligned with the baseline, based on monthly equity correlation of 0.960, projection RMSE of $21,789, normalized RMSE of 4.867, and path wander ratio of 0.621. Correlation still describes directional similarity, but RMSE and path wander ratio show how far the realized path has wandered from projection over the same window. Monte Carlo context is cautionary: actual forward equity is $67,575, gain percentile is 97% (near the top of the simulated distribution), and drawdown percentile is 99% (in the worst decile for drawdown stress). Taken together, the system shows meaningful deterioration in incubation.
A readiness reading of 4 out 8 indicates this system right now has degraded to a point where caution and I mean extreme caution should be used in your decision to trade this strategy. The major factors influencing rating are:
Return Attainment: 1.907 – — This indicates the system has achieved 190.7% of its historically expected return during the incubation/trading period. In practical terms, the strategy is generating returns at nearly twice the pace implied by its historical baseline.
Path Wander Ratio:0.621 — This indicates that the actual equity path is deviating from the projected path by a meaningful amount relative to the total expected move over the incubation/trading period. Put simply, the system is not wildly off course, but it is no longer tracking the historical baseline tightly.
Drawdown Stress:2.67 — This indicates that the actual worst drawdown has expanded to roughly 2.7 times the level suggested by the system’s historical baseline. Put simply, the strategy may still be generating return, but it is doing so while absorbing far more pain than its historical profile would justify.
Hindsight is always 20/20, and it is easy to say now that you should have stuck with the system. But with a large sample of out-of-sample trades showing this degree of deterioration, if I had to choose between staying with it, abandoning it entirely, or temporarily shutting it down, I would probably step aside and wait for conditions to settle down. Remember, not trading is an algorithm too. Having the right tools to make this kind of decision is paramount, because they give you an evidence-based framework for explaining and defending your reasoning.
The Power of Incubation: Is Your Best System Collecting Dust?
How many systems do you have sitting on your shelf? I personally have at least a hundred, probably more. In this business, a little dust is not always a bad thing.
Figuratively speaking, the more “dust” a system has collected, the more real-time incubation it has endured. And that gives you something far more valuable than any backtest: pure, unadulterated out-of-sample evidence.
Seeds Waiting to Be Planted
Algorithmic trading development rarely produces just one system. It creates a trail of offshoots—versions that may have looked unremarkable or even mediocre during the initial build. Yet many of these forgotten systems are really just seeds waiting for the right environment.
When you revisit them months or even years later, you may find that a strategy which struggled in 2022 has bloomed into a powerhouse in 2026. Without a framework to measure that growth, you would never know.
Why You Need an Incubation Framework
Most traders revisit old systems by simply eyeballing an equity curve. An incubation framework goes much deeper by providing:
Historical Context: Does the dusty system’s recent performance still match its original DNA?
Regime Readiness: Has the market finally moved into the regime this offshoot was designed for?
The Go/No-Go Signal: A quantitative way to decide whether a seed is finally ready to be moved from the shelf to the server.
TS-SystemChecker software
TS-System Check Control Panel
A Tool Built for the Journey
I built TS-SystemChecker because, after decades at Futures Truth and years of developing my own strategies, I needed a better way to cut through the emotional fog that surrounds system evaluation. I didn’t design TS-SystemChecker to be a black box or some kind of get-rich-quick shortcut. I built it because, after decades at Futures Truth and years of developing my own strategies, I wanted a better way to cut through the emotional fog that surrounds system evaluation.
Whether you are a retail trader focused on refining one core system, or a developer like me with a shelf full of offshoots, this framework was built for that journey.
For the specialist: If you have one system you live and die by, the deep-dive analysis helps define its boundaries of truth. You can begin to see whether a drawdown is simply part of the system’s normal character or evidence of something more structural.
For the portfolio manager: If you are tracking a library of ideas, the Batch Analysis feature helps you monitor many systems at once. Import the trade files, review the evidence, and identify which seeds may finally be ready to move from the shelf to a live account.
Looking Beneath the Surface
At the end of the day, this is why I built TS-SystemChecker. Traders need more than opinions, hope, or fear. They need a framework grounded in evidence.
That is the real purpose of this tool: not to make decisions for you, but to help you make better ones.
Monte Carlo methods took off in the 1940s during wartime research at Los Alamos, when scientists needed a practical way to estimate outcomes for complex systems that couldn’t be solved with a single clean equation. Trading has the same problem: there’s no tidy formula that can tell you the order your wins and losses will arrive in—and that order is where luck lives.
So we do the next best thing: we add randomness on purpose. Monte Carlo repeatedly reshuffles the same trade outcomes to create many plausible equity paths, revealing how smooth (or brutal) the ride can be even when the system’s edge stays the same.
“No matter how sophisticated our choices, how good we are at dominating the odds, randomness will have the last word.” — Nassim Nicholas Taleb, Fooled by Randomness
What Monte Carlo does in trading
In trading system analysis, the “Monte Carlo move” is straightforward: you take your historical list of trade results (P/L per trade), then you randomly reshuffle (or resample) that list thousands of times. Each reshuffle produces a new, plausible equity curve built from the same underlying trade outcomes. From there, you measure the things that actually determine whether a system is tradeable—how deep the drawdowns get, how long the slumps can last, and how often the path gets ugly enough to force you to quit or cut size.
This doesn’t predict the future. It answers a different (and more practical) question:
Given the trade outcomes you’ve already seen, how good—or how bad—can the ride get due to sequencing alone?
That’s the value, or is it?
Why traders debate the value of Monte Carlo
Why some traders love it
It exposes fragility that a single backtest can hide. A backtest is one historical path—one specific order of wins and losses. Monte Carlo reshuffles that order to show other plausible paths. If a strategy only “works” when winners show up early, Monte Carlo will expose that quickly.
It turns vague fear into a measurable risk. Traders feel risk but struggle to quantify it. Monte Carlo lets you define a failure line (for example, “equity falls below 60% of starting capital”) and estimate how often that happens across thousands of simulated lives. You may still trade it—but now you’re choosing with a probability, not a gut feeling.
It helps you size the system rationally. Most blow-ups aren’t caused by a bad system—they’re caused by a decent system traded too big. By running the same trades under different starting capital (or leverage), Monte Carlo shows where the strategy becomes survivable. It often reveals a capital/size “threshold” where ruin risk drops and drawdowns become tolerable.
Why some traders hate it
It assumes the future behaves like the past. Monte Carlo can’t detect regime change. If your edge only works in certain “market moods” (trending vs choppy, low-vol vs high-vol), the simulation may look great right up until the market stops playing that game.
It assumes trades can be shuffled like a deck of cards. Many Monte Carlo runs treat each trade as an independent draw from the same bag of outcomes. Real systems aren’t that clean—markets come in streaks and clusters (volatility spikes, choppy stretches, correlation breaks), and those dependencies don’t always survive a simple reshuffle. Monte Carlo still helps measure sequence risk, but it isn’t a full market simulator.
It can punish good systems—and flatter lucky ones. A solid system can look worse if its history includes a few rare “tail” events—Monte Carlo will replay those tails in many sequences. Meanwhile, a strategy that enjoyed an unusually favorable historical run can look sturdier than it deserves, because the simulation is only as honest as the sample you feed it.
So, it’s not garbage… but it’s not gold automatically either.
Monte Carlo is a tool. Like any tool, it can be used well or used blindly.
For these tests, I used my Streamlit-based Monte Carlo “Trade Flight Simulator.” You paste a column of trade P/L and the simulator generates:
Risk of Ruin based on a user-defined ruin line
Median drawdown across thousands of randomized equity paths
Worst-case outcomes (1st percentile)
Distribution visuals (“broom chart” equity fan + destination histogram)
Scaling table across start equity levels
Key settings used here
Ruin threshold: 60% of starting equity
Position size: 1 contract per trade
Execution costs: $40 per trade included in the trade list results you pasted
Horizon: number of trades pasted (the simulator runs “N trades” each life)
Optional CAGR is computed from first/last trade dates when provided
System #1: Mean Reversion on the Mini Nasdaq (MNQ)
~$40 execution costs, ~20 years
Start Equity
Risk of Ruin
Median DD
Annual Return
Worst Case (1st %)
$25,000
30%
42.9%
12.9%
$85,019
$31,250
14%
36.2%
11.7%
$80,747
$37,500
8%
32.2%
10.8%
$93,072
$43,750
4%
30.1%
10.0%
$78,308
$50,000
1%
26.4%
9.6%
$81,352
$56,250
1%
25.2%
8.8%
$93,765
$62,500
0%
24.4%
8.4%
$77,907
$68,750
0%
23.0%
8.1%
$81,076
$75,000
0%
20.6%
7.7%
$81,108
$81,250
0%
19.1%
7.4%
$89,028
$87,500
0%
18.9%
7.0%
$81,982
System #1 — Mean Reversion (MNQ)
At $25,000 start equity
Risk of Ruin: 30%
Median Drawdown: 42.9%
Annual Return: 12.9%
Worst Case (1%): +$85,019
Prob > 0: 99.9%
At $50,000 start equity (“still not comfortable”)
Risk of Ruin: 1%
Median Drawdown: 26.4%
Annual Return: 9.6%
At $62,500 start equity (“stability zone”)
Risk of Ruin: 0%
Median Drawdown: 24.4%
Annual Return: 8.4%
What Monte Carlo reveals about this system
This is what a tradeable but under-capitalized system looks like.
The edge is real (the probability of finishing positive is essentially ~100%), but the sequence risk at low starting equity is still brutal:
A 30% risk of ruin at $25k (with a 60% ruin line) is not a rounding error.
Even at $31,250, ruin risk is still 14%.
The system doesn’t start to feel “professional” until you get into the $60k+ range, where ruin drops to 0% and median drawdowns settle into the mid-20% area.
Monte Carlo’s message: If you want this system to behave like something you can actually stick with, you don’t optimize parameters — you capitalize it properly.
System #2: Trend Following on Crude Oil
~$40 execution costs, ~20 years
System #2 — Trend Following (Crude)
Start Equity
Risk of Ruin
Median DD
Annual Return
Worst Case (1%)
$25,000
68%
89.7%
8.7%
-$99,928
$31,250
58%
80.7%
7.8%
-$95,663
$37,500
47%
71.3%
7.1%
-$100,991
$43,750
40%
64.1%
6.5%
-$111,564
$50,000
31%
58.3%
6.2%
-$98,846
$56,250
28%
57.0%
5.5%
-$94,594
$62,500
22%
51.1%
5.3%
-$100,349
$68,750
19%
49.9%
4.8%
-$103,016
$75,000
16%
47.2%
4.5%
-$112,968
$81,250
12%
42.3%
4.5%
-$98,345
$87,500
11%
42.1%
4.0%
-$98,228
At $25,000 start equity
Risk of Ruin: 68%
Median Drawdown: 89.7%
Annual Return: 8.7%
Worst Case (1%): -$99,928
Prob > 0: 87.3%
At $50,000 start equity
Risk of Ruin: 31%
Median Drawdown: 58.3%
Annual Return: 6.2%
Worst Case (1%): -$98,846
Prob > 0: 90.1%
At $81,250 start equity
Risk of Ruin: 12%
Median Drawdown: 42.3%
Annual Return: 4.5%
Worst Case (1%): -$98,345
Prob > 0: 86.4%
At $87,500 start equity
Risk of Ruin: 11%
Median Drawdown: 42.1%
Annual Return: 4.0%
Worst Case (1%): -$98,228
Prob > 0: 87.1%
What Monte Carlo reveals about this system
This is a classic crude trend-following signature: the system can be profitable over time, but the path can be violently unforgiving—especially when under-capitalized.
The probability of finishing positive is only in the mid-to-high 80% range, not “near-certain.”
At $25,000, the system is living on the edge: 68% risk of ruin with an 89.7% median drawdown.
Even after you scale up, the ride is still rough. At $81,250, ruin risk is still 12% with a 42.3% median drawdown.
The most important tell is the left tail: the 1% worst-case outcome is negative at every starting equity you tested (roughly –$94,594 to –$112,968). That means there are plausible sequences where the system not only suffers deep drawdowns, but ends the run down money—even with larger starting capital.
Monte Carlo’s message: This isn’t just a “start with more money” situation. Increasing capital helps, but the strategy’s tail risk remains severe. If you trade this, you need materially more capitalization, smaller sizing, or a risk overlay—because crude can deliver adverse sequences that this system does not comfortably absorb.
Which system is “superior” under your ruin rule?
You asked earlier: with a 60% ruin line and 1 contract per trade, does Monte Carlo reveal superiority?
Yes — because it reframes superiority as:
Which system survives at realistic starting equity levels with tolerable drawdowns?
Under-capitalized start: both are dangerous
At $25k, both systems are dangerous under the 60% ruin definition:
MNQ MR: 29% ruin, 41% median DD
Crude TF: 48% ruin, 55% median DD
So if someone insists on $25k and 1 contract, System #1 is clearly less fragile than System #2.
Once you move into realistic capital, System #1 stabilizes sooner
MNQ MR drops into “sane” ruin probabilities faster:
MNQ MR hits ~0% ruin by $56,250
Crude TF doesn’t really calm down until $75k–$81k
That’s not a judgment against trend following — it’s a reminder that instrument volatility matters and crude can be a different animal.
If you define “superior” as best risk-adjusted scaling
Based on your tables:
MNQ mean reversion looks easier to scale under your assumptions
Crude trend following can still be very viable, but it demands more capitalization to get into the same comfort zone
Monte Carlo didn’t make either system “good” or “bad.” It made the capital requirements and sequence risk visible.
The visuals I include from the Streamlit app
System #1 Mean Reversion on the NQ
The Journey (“broom chart”) Shows the median equity path with a confidence band. Great for communicating “how rough can the ride get?”
Broom Chart
The Destination (ending equity histogram) Think of each green bar as a bucket of endings. After 1,000 randomized runs, some endings cluster in the middle (the “typical” outcomes), while a smaller number land in the tails (the “lucky” and “unlucky” sequences). The dashed line marks your starting equity ($25,000). If the histogram sits mostly to the right, the system usually finishes positive. If a meaningful chunk sits to the left, that’s your “this can end down” reality—even with the same system and the same trades, just a different order.
Destination Histogram
Efficiency cloud (drawdown vs net profit scatter)
Each dot = one simulated run (“one life”).
Left to right (x-axis) = max drawdown during that run (more right = more pain).
Down to up (y-axis) = net profit at the end (higher = more gain).
The dotted lines mark the median drawdown and median profit, splitting the plot into four zones.
Best zone:upper-left (good profit with smaller drawdowns).
Worst zone:lower-right (big drawdowns with poor outcomes).
If most dots sit upper-left, the system is efficient. If the cloud spreads far right, the system’s edge may be real, but the ride can be brutal unless you reduce size or add capital.
Efficiency Cloud
Pros and cons of Monte Carlo (in plain English)
Pros
It highlights sequence risk that backtests hide
It gives you a practical scaling map
It converts drawdown fear into probability
It forces you to confront whether your system is truly robust or just lucky
Cons
Garbage in, garbage out (your trade list must be clean)
It assumes your future trade distribution resembles the past
It doesn’t simulate regime shifts (it’s not a market model)
It can create false confidence if you treat it as prophecy
Monte Carlo is not a crystal ball. It’s a stress test.
Conclusion: Garbage or Gold?
Monte Carlo is gold when it’s used as a risk lens.
It’s garbage only when people use it as a substitute for thinking — or when they treat it as a promise about the future.
For me, the biggest takeaway from these two systems is simple:
A profitable system can be untradeable if it’s under-capitalized.
Monte Carlo makes that obvious — quickly and brutally.
And it gives you something most trading metrics do not: a realistic map from “this looks good” to “this can survive.”
If you want to know what your system really feels like under stress, run it through my free Monte Carlo Trade Flight Simulator (Streamlit). Paste your trade list, set a starting equity, and it will generate a distribution of possible equity paths—so you can see the range of outcomes, not just the single backtest line. In a minute or two you’ll know whether your strategy is sturdy (most paths survive and grow) or fragile (too many paths crater early), and you’ll get practical numbers like “typical drawdown,” “worst-case runs,” and “probability of finishing above zero.”
Trades vs. Time: Two Monte Carlo Styles
Monte Carlo has to “shuffle” something: you can shuffle trades or you can shuffle time periods (daily/weekly/monthly returns). Trade-shuffling is great for a single system because it keeps each trade intact—entry and exit stay married—so you’re mainly testing how sensitive results are to the order trades arrive.
Devil’s Advocate: shuffling time can feel less “real,” because it breaks those trade narratives. A multi-day trade becomes a series of daily fragments, and once you reshuffle daily P/L you can build equity paths that no single set of trades could have produced exactly.
That’s the tradeoff TS-PortfolioMerge makes on purpose. It builds a daily mark-to-market equity curve (open positions are revalued each day), then resamples those daily equity changes so every system stays aligned to the same calendar. This isn’t about “reinvesting” or scaling up contracts—it’s about equity path risk: the way good and bad stretches of days create drawdowns, recovery difficulty, and survival pressure for a portfolio even when trade size stays constant.
A Bare-Bones Turtle Algorithm for Gauging Trend-Following Conditions
The core Turtle rules were fully mechanical, but several operational choices, such as position sizing nuances, market selection, roll/contract handling, and execution practices were left to judgment or circumstance. Many would argue the philosophy behind the Turtles mattered as much as the rules themselves, and differing interpretations of that philosophy go a long way toward explaining why their results diverged so widely. The mechanics, however, are straightforward: you can distill them from the published books and courses, strip them down even further, and apply the resulting rule set across a broad portfolio to take the pulse of trend-following today.
I’ve worked with the Turtle framework for many years, coded numerous variants, and even compared notes with a handful of original Turtles. If any method can “take the temperature” of market trendiness, this one can. This system synthesizes a shorter-term trend mechanism (that limits execution based on the prior outcome) with a true longer term trend following entry and exit method (two months of data are used to determine entry). Short-term trading is difficult and often falls victim to over trading. The shorter-term entry is used to try and capitalize on the genesis of a big trend. Preventing another trade after a winner is one method of reducing trading and chop. If the short-term break out turns into a trend and entry is prevented, then the 55-day break out is there to capture it. Below are the rules I extracted to build a fully mechanical, bare-bones algorithm for that purpose.
Rules Used in This Analysis
Conventions & Definitions
Breakout (stop basis): Enter on a stop when price exceeds the specified lookback extreme by 1 tick (or exactly at the extreme if your platform supports that).
N: 20-day weighted Average True Range (WATR) used for both systems.
Risk stop (volatility stop): A stop placed 2×N from the entry price.
Swing stop: For System #1, use the 10-day highest high/lowest low; for System #2, use the 20-day highest high/lowest low.
Closest stop wins: The active protective stop at any time is the tighter of the risk stop and the swing stop.
Loser vs. non-loser (for System #1’s gating rule):
A trade that is stopped out by 2×N is a loser.
A trade that exits via the 10-day swing stop (even if it’s a loss) is not counted as a loser for gating.
Profitable exits via the 10-day swing stop are obviously not losers.
System #1 — 20-Day Breakout (Conditional)
Purpose: Only take the next 20-day breakout if the most recent 20-day breakout resulted in a 2×N loss.
Entry condition (gated):
Compute the 20-day Donchian channel.
You may only take a long (new 20-day high) or short (new 20-day low) breakout if the last System #1 trade ended with a 2×N risk stop.
If the last System #1 trade exited via the 10-day swing stop, it does not unlock the gate.
Initial protective stops (at entry):
Risk stop: 2×N from entry.
Swing stop: Opposite extreme of the past 10 days (lowest low for longs, highest high for shorts).
Use the tighter of the two stops at all times (“closest stop wins”).
Exit rules:
Exit if price hits the active stop (risk or swing).
Bookkeeping for gating:
If exit was the 2×N risk stop, mark the trade as a loser (this unlocks the gate for the next entry).
If exit was the 10-day swing stop, do not mark as a loser (gate remains locked).
Always evaluating: System #1’s breakout logic runs continuously, but entries are allowed only when the gate is unlocked by a prior 2×N loss.
System #2 — 55-Day Breakout (Always On)
Purpose: Classic trend capture that runs regardless of System #1’s state; does not affect System #1’s gating.
Entry condition (ungated):
Enter long on a 55-day high breakout; enter short on a 55-day low breakout.
Initial protective stops (at entry):
Risk stop: 2×N from entry.
Swing stop: Opposite extreme of the past 20 days (lowest low for longs, highest high for shorts).
Use the tighter of the two stops at all times.
Exit rules:
Exit if price hits the active stop (risk or swing).
Isolation from System #1:
System #2 trades and outcomes do not influence System #1’s “last-trade-was-a-loser” gate (also known as a filter).
The Portfolio
Currencies (CME FX)
Preferred name
Short
Futures ticker
Australian Dollar
AUD
@AD (6A)
British Pound
GBP
@BP (6B)
Canadian Dollar
CAD
@CD (6C)
Euro
EUR
@EC (6E)
Japanese Yen
JPY
@JY (6J)
Swiss Franc
CHF
@SF (6S)
Rates (CBOT)
Preferred name
Short
Futures ticker
30-Year U.S. Treasury Bond
30Y
@US (ZB)
10-Year U.S. Treasury Note
10Y
@TY (ZN)
5-Year U.S. Treasury Note
5Y
@FV (ZF)
Equity/Index
Preferred name
Short
Futures ticker
E-mini S&P 500
ES
@ES (CME)
U.S. Dollar Index
DXY
@DX (ICE)
Metals (COMEX/NYMEX)
Preferred name
Short
Futures ticker
Gold
XAU
@GC
Copper
Cu
@HG
Silver
XAG
@SI
Palladium
Pd
@PA=11INC
Platinum
Pt
@PL
Energies (NYMEX)
Preferred name
Short
Futures ticker
RBOB Gasoline
RBOB
@RB
Heating Oil
HO
@HO
WTI Crude Oil
WTI
@CL
Henry Hub Natural Gas
NatGas
@NG
Grains/Oilseeds (CBOT)
Preferred name
Short
Futures ticker
Soybeans
Beans
@ZS
Corn
Corn
@ZC
Rough Rice
Rice
@ZR
Wheat (SRW)
Wheat
@ZW
Soybean Meal
Meal
@ZM
Livestock (CME)
Preferred name
Short
Futures ticker
Feeder Cattle
Feeders
@FC (GF )
Live Cattle
LiveCat
@LC (LE )
Lean Hogs
Hogs
@LH (HE)
Softs (ICE)
Preferred name
Short
Futures ticker
Frozen Concentrated Orange Juice
OJ
@OJ
Sugar No. 11
Sugar
@SB
Cotton No. 2
Cotton
@CT
Coffee “C”
Coffee
@KC
Lumber
Lumber
@LBR = @LB legacy
Market Normalization (Fixed-Fractional Sizing)
To level the playing field across markets, I used fixed-fractional position sizing keyed to the Turtle “quick” 20-day ATR.
Risk budget per trade
Account equity =$250,000
Fraction at risk per trade =2%
Dollar risk per trade: = × = 0.02 × 250,000 = $5,000
Contracts to trade
Let ATR = 20-day (Turtle quick) Average True Range in price units
Let BPV = Big Point Value (dollars per 1.0 move)
Dollar risk per 1 contract: ATR × BPV
Position size (contracts):
Contracts =⌊ / ATR × BPV⌋
In words: allocate $5,000 of risk to each trade and size the position by dividing that risk by the market’s expected dollar move (ATR×BPV). Round down to an integer.
Notes & conventions
ATR is the 20-day Turtle quick ATR (same used in the rules).
Use the correct BPV for each contract (e.g., ES $50/pt, CL $1,000/pt, SI $5,000/pt).
Enforce at least on contract per signal.
$50 slippage and $10 commission per round turn.
Results
Large portfolio performance on Bare Bones Turtle
This equity curve is very typical across the spectrum of most trend following systems. There have been big years to keep the trend following momentum going – recently 2008, 2010, 2014, 2018, 2020.
Big Years – pushes the popularity of Trend Following
Many times, the futures and commodity markets are there to benefit from global events such as the banking collapse (2008) and the pandemic (2020).
Over the years, markets have fallen in and out of favor with Trend Following. The best market over the past twenty years or so turned out to be sugar. With its smaller size and associated volatility and trends it was the clear winner.
Many HOT SPOTS on the Correlation Heat Map
Pearson Correlation Matrix
But, what about smaller accounts?
There exist sub portfolios with better profit to draw down ratios. If you could only choose ten markets and wanted to know the best combination, you can do this with my TS-PortfolioMerge software. In fact, all the metrics and images I have shown in this post were generated with TS-PortfolioMerge. If your budget only allows for 10 markets and you want to evaluate every combination you will need to wait a while for TS-PM to run through every combination.
Search space C(37,10) = 348,330,136 (subset) – yes that is 300 million combinations. Just set up your computer for overnight processing.
But if you want a speedy answer, that will approximate the entire search space you can do that as well.
Run the speedy version multiple times to see if the same portfolio bubbles to the top. If you continue getting different portfolios, you can run the exhaustive mode. Here the best 10 markets were:
Here you have two currencies (EC and JY), one metal (HG), two energies (HO and RBOB), one interest rate (TY), sugar, lumber, soybean meal and lean hogs. But are we guilty of cherry picking? Maybe the Monte Carlo analysis will provide some insight.
Monte Carlo Analysis on 10 of the best combination from the Speedy output.
Conclusion
Trend Following as of late October 2025 is doing well and doing as expected. The pandemic pulled the algorithm out of the doldrums and positive years have been banked since. The current year looks like the exception, but we still have two months left. With the Gold move you would think 2025 would have been a banner year. The Trend is STILL OUR FRIEND.
Email me if you would like my code for my bare bones Turtle system, I utilized to create all these results. The code includes the human curated LAST TRADE WAS A LOSER function.
In today’s trading environment where a single stock dominates an index, you must be careful with your order placement (if you can) around potentially large news events.
I am late with this post, but my client (I program for him) suffered through a Perfect Slippage Storm. A short-term system is only as good as its ability to be properly executed. On August 27th, 2025, NVIDIA announced after the market close. According to ChatGPT.
Yes—that timing lines up with Nvidia’s earnings release hitting after the bell. On Wed, Aug 27, 2025, outlets were primed for the NVDA press release around 4:20 pm ET; live blogs called out that exact time window, and NVDA headlines/press release started landing shortly after, with shares dipping in early after-hours. That kind of instant move in NVDA typically ripples straight into NQ.
Check out the following graphic.
The Perfect Slippage Storm!
Can this really happen?
Come on – this is a 5-minute bar, right? A lot of things can happen in five minutes. I was a futures broker for many years and my rule of thumb during my tenure was you MAY get out at the low of the minute bar if there is a hiccup and your sell stop is blown. Here is a one-minute chart.
Some orders were filled at the tick up on the 2nd minute bar.
My client wasn’t lucky this day and got filled near the low of the 2nd minute bar. He was using a % trailing stop and when the high breached his threshold his protective stop was cancelled, and the new stop was implemented. All this activity takes time. And this strategy is professionally managed.
Why was this a perfect storm?
The report pop printed a new intraday high, likely tripping resting buy-stops and in this case pulling trailing protective stops tighter. Those sell-stops then fired into a thinning book after 4:00 p.m. ET, where Nasdaq futures liquidity is razor thin. Some orders were rejected or re-priced and ended up converting to market, worsening slippage. In this case, my client would have been better off if the trailing-stop threshold hadn’t been touched.
Electronic Trading and Fast Market Conditions and Not Held Order!
You believed the trade was up $400, but your day-end statement shows a loss of –$3,400. That disconnect usually comes from execution during a fast market. When your order is not held, the broker (or algo) has time/price discretion and no obligation to fill at a specific price. In a sudden air-pocket, quotes vanish and price gaps; the broker can’t predict the next print, so the only thing he can do is hit the first available liquidity. The result is slippage and a gaping difference between what is on the screen on what is in your pocket or the lack thereof.
A Stop Limit order can help during spikes or down drafts
This type of order is not universally available – especially when using algos.
A buy stop-limit order is a two-part order used to enter long above the market (or cover a short) with price control.
Stop price (trigger): When the market trades at or above this price, your order activates.
Limit price (cap): Once activated, the order becomes a limit buy at your limit price (or better). It will not pay more than the limit.
What should my client do in the future?
He tested his strategy over 15 years of data and felt secure enough to trade the system. He knows that this market action could have just as easily gone in his favor. Had the initial reaction carried on, he may have made a nice profit. Should he augment his strategy to get out at the end of the day and then get back in – step over post-closing reports? Maybe, but there is always the potential of slippage on this out and back in trade. Also, you would need to use discretion as to when a handful of stocks controls the entire index.
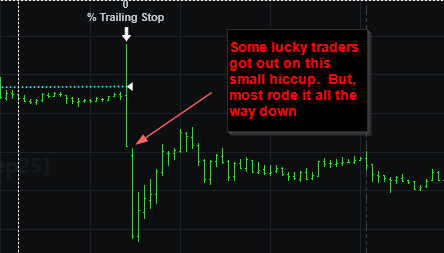
Percent trailing stops only help if your profit trigger is meaningfully large and you’re willing to give back a realistic slice of that profit.
When a client shows me an equity curve that looks too good to be true, my first question is whether they’re using a percent trailing stop. I hope they say no—but usually it’s yes. Then I ask two things:
What’s the profit threshold that arms the trail?
How much are you willing to give back once it arms?
If the threshold is small and the give-back is ~20% or less, I know we’re in Best-Case Scenario Syndrome: backtests assume friendly fills. Platforms like TradeStation or MultiCharts will print a theoretical fill on every trade, but as we saw earlier, the gap between theory and actual can be huge.
You must accept that slippage is going to occur
If you don’t then you cannot trade. You might come back at me and say: “Well, I will only use stop limit orders.” That is great. but what about when exiting a trade. “I will only develop a strategy that enters on limits – that way I can cut slippage in half.” That is definitely a possibility. “I will execute myself and forgo the convenience of algo order placement.” Well, you better quit your day job and trade during the day.
When a function accesses a previously stored value of one of its own variables, it essentially becomes a “series” function. Few programming languages offer this convenience out of the box. The ability to automatically remember a function’s internal state from one bar (or time step) to the next is known as state retention. In languages like Python, achieving this typically requires using a class structure. In Module #2 of my Easing into EasyLanguage Academy, I explained why EasyLanguage isn’t as simple as its name implies—yet this feature shows how its developers aimed to simplify otherwise complex tasks.
If you’ve ever worked with functions with memory that exchange data using a numericRef input, you’ve essentially been using a pseudo-class—a form of object-oriented programming in its own right. EasyLanguage includes a robust object-oriented library (with excellent resources by Sunny Harris and Sam Tennis – buy their book on Amazon), yet you’re confined to its built-in functionality since it doesn’t yet support user-defined class structures. Nonetheless, the series functionality combined with data passing brings you remarkably close to a true object-oriented approach—and the best part is, you might not even realize it.
Example of a Series Function
I was recently working on the Trend Strength indicator/function and have been mulling this post over for some time, so I thought this would be a good time to write about it. The following indicator to function conversion will create a function of type series (a function with a memory.) The name series is very appropriate in that this type of function runs along with the time series of the chart. It must do this so it can reference prior bar values.
You can ensure a function is treated as a series function in two ways:
Using a Prior Value: When you reference a previous value within the function, EasyLanguage automatically recognizes the need to remember past data and treats the function as a series function.
Setting the Series Property: Alternatively, you can explicitly set the function’s property to “series” via a dialog. This instructs EasyLanguage to handle the function as a series function, ensuring that state is maintained across bars.
Manually Set the Function to type Series
Importantly, regardless of the function’s name or even if it’s called within control structures (like an if construct), a series function is evaluated on every bar. This guarantees that the historical data is consistently updated and maintained, which is essential for accurate time series analysis.
Converting an indicator to a function
You can find a wide variety of EasyLanguage indicators online, though many are available solely as indicators. This is fine if you’re only interested in plotting the values. However, if you want to incorporate an indicator into a trading strategy, you’ll need to convert it into a function. For calculation-intensive indicators, it’s best to follow a standard prototype: use inputs for interfacing, perform calculations via function calls, and apply the appropriate plotting mechanisms. By adhering to this development protocol, your indicator functions can be reused across different analysis studies, enhancing encapsulation and modularity. Fortunately, converting an indicator’s calculations into a function is a relatively straightforward process. Here is indicator that I found somewhere.
Inputs: ShortLength(13), // Shorter EMA length LongLength(25), // Longer EMA length SignalSmoothing(7); // Smoothing for signal line Vars: DoubleSmoothedPC(0), DoubleSmoothedAbsPC(0), TSIValue(0), SignalLine(0); // Price Change (PC) Value1 = Close - Close[1]; // First Smoothing (EMA of PC and |PC|) Value2 = XAverage(Value1, LongLength); Value3 = XAverage(AbsValue(Value1), LongLength); // Second Smoothing (EMA of First Smoothed Values) DoubleSmoothedPC = XAverage(Value2, ShortLength); DoubleSmoothedAbsPC = XAverage(Value3, ShortLength); // Compute TSI If DoubleSmoothedAbsPC <> 0 Then TSIValue = 100 * (DoubleSmoothedPC / DoubleSmoothedAbsPC);
// Compute Signal Line SignalLine = XAverage(TSIValue, SignalSmoothing); // Plot the TSI and Signal Line Plot1(TSIValue, "TSI"); Plot2(SignalLine, "Signal");
TSI via Web
Now we can functionize it.
Below is an example of how you might convert an indicator into a function called TrendStrengthIndex. Notice that the first change is to replace any hard-coded numbers in the indicator’s inputs with parameters declared as numericSimple (or numericSeries where appropriate). This allows the function to accept dynamic values when called. Not to give anything away, but you can also declare variables as numericRef, numericSeries, numericArrayRef, string, stringRef, and stringArrayRef. Let’s not worry about these types right now.
inputs: ShortLength(numericSimple), // Shorter EMA length LongLength(numericSimple), // Longer EMA length SignalSmoothing(numericSimple); // Smoothing for signal line
Inputs must be changed to function nomenclature
Below is an example function conversion for the TrendStrengthIndex indicator. The plot statements have been commented out since—rather than plotting—the function now passes back the calculated value to the calling program.
Vars: DoubleSmoothedPC(0), DoubleSmoothedAbsPC(0), TSIValue(0), SignalLine(0); // Price Change (PC) Value1 = Close - Close[1]; // First Smoothing (EMA of PC and |PC|) Value2 = XAverage(Value1, LongLength); Value3 = XAverage(AbsValue(Value1), LongLength); // Second Smoothing (EMA of First Smoothed Values) DoubleSmoothedPC = XAverage(Value2, ShortLength); DoubleSmoothedAbsPC = XAverage(Value3, ShortLength); // Compute TSI If DoubleSmoothedAbsPC <> 0 Then TSIValue = 100 * (DoubleSmoothedPC / DoubleSmoothedAbsPC);
// Compute Signal Line SignalLine = XAverage(TSIValue, SignalSmoothing); // Plot the TSI and Signal Line //Plot1(TSIValue, "TSI"); commented out //Plot2(SignalLine, "Signal"); commented out TrendSTrengthIndex = TSIValue;
Functionalize It!
This works great if we just want the TrendStrengthIndex, but this indicator, like many others has a signal line. The signal line for such indicators is usually a smoothed version of the main calculation. Now you could do this smoothing outside the function, but wouldn’t it be easier if we did everything inside of the function?
Oh no! I need to pass more than one value back!
If we just wanted to pass back TSIValue all we need to do is assign the name of the function to this value.
Passing values by reference
We can adjust the function to return multiple values by defining some of the inputs as numericRef. Essentially, when you pass a variable as a numericRef, you’re actually handing over its memory address—okay, let’s get nerdy for a moment! This means that when the function updates the value at that address, the calling routine immediately sees the change, giving the variable a kind of quasi-global behavior. Without numericRef, any modifications made inside the function stay local and never propagate back to the caller. Not only is the function communicating with the calling strategy or indicator it is also remember its own stuff for future use. Take a look at this code.
inputs: ShortLength(numericSimple), // Shorter EMA length LongLength(numericSimple), // Longer EMA length SignalSmoothing(numericSimple), // Smoothing for signal line
// Force series FUNCTION BEHAVIOR Value4 = Value3[1]; // Price Change (PC) Value1 = Close - Close[1]; // First Smoothing (EMA of PC and |PC|) Value2 = XAverage(Value1, LongLength); Value3 = XAverage(AbsValue(Value1), LongLength);
// Second Smoothing (EMA of First Smoothed Values) DoubleSmoothedPC = XAverage(Value2, ShortLength); DoubleSmoothedAbsPC = XAverage(Value3, ShortLength); // Compute TSI If DoubleSmoothedAbsPC <> 0 Then TrendStrength.index = 100 * (DoubleSmoothedPC / DoubleSmoothedAbsPC);
// Compute Signal Line TrendStrength.signal = XAverage(TrendStrength.index, SignalSmoothing);
TrendStrengthIndex = 1;
Is this a function or is it a class?
There is a lot going on here. Since we are storing our calculations in the two numericRef inputs, TrendStrength.index and TrendStrength.signal the function name can simply be assigned the number 1. You only need to do this because the function needs to be assigned something, or you will get a syntax error. Since we are talking objects, I think it would be appropriate to introduce “dot notation.” When programming with objects you access the class members and methods buy using a dot. If you have an exponential moving average class in python you would access the variables and functions (methods) in the class like this.
class ExponentialMovingAverage: # Class-level defaults serve as initial values. alpha = 0.2 # Default smoothing factor ema = None # EMA starts as None
def update(self, price): """ Update the EMA with a new price.
Parameters: price (float): The new price to incorporate.
Returns: float: The updated EMA value. """ # If ema is None, this is the first update if self.ema is None: self.ema = price else: self.ema = self.alpha * price + (1 - self.alpha) * self.ema return self.ema
# Create an instance of the class. ema_calculator = ExponentialMovingAverage()
# Dot notation to access the class attribute. print("Alpha value:", ema_calculator.alpha)
# Dot notation to access the EMA attribute before any updates. print("Initial EMA (should be None):", ema_calculator.ema)
# Dot notation to call the update method. ema_value = ema_calculator.update(10) print("EMA after update with 10:", ema_value)
Using dot notation to extract values from a class
Since you are using EasyLanguage and a series function, you don’t have to deal with something like this. On the surface this looks a little gross but coming from a programming background this is quite eloquent. I only show this to demonstrate dot notation. In an attempt to mimic dot notation in the EasyLanguage function, I simply add a period ” , ” to the input variable names that will return the numbers we need to plot. Take a look at the nomenclature I am using.
I am using the function name a ” . ” and an appropriate variable name. This is not necessary. Historically, input names that were modified within a function were preceded by the letter “O.” In this example, Oindex and Osignal. This represented “output.” Remember these naming conventions are all up to you. Here is the new indicator using our EasyLanguage “Classy” function and our pseudo dot notation nomenclature.
Take a look at how we access the information we need from the function calls.
You might be surprised to learn that you may have been doing object-oriented programming all along without realizing it. Do you prefer the clarity of dot notation for accessing function output, or would you rather stick with a notation that uses a big “O” combined with the input name to represent functions with multiple outputs? Also, notice how each function call behaves like a new instance—the internal values remain discrete, meaning that each call remembers its own state independently. In other words, each function call remembers its own stuff.
Two distinct function values from the same function – called twice on the same bar.
Exporting Strategy Performance XML files that use 15 years of 5-minute bars can be cumbersome. Using Maestro can be cumbersome too. I know there are great programs out there that will quickly analyze the XML files and do what we are about to do plus a bunch more. But if you want to do it yourself, try working with 224,377 KB files.
If you want to do a quick merge of equity curves of different markets or systems use this simple method. That is if you have Python, MatPlotLib and Pandas installed on your computer. Installing these are really simple and everybody is doing it. I created this script with the help of a paid version of ChatGPT.
Using Python et al. to plot combined equity curve.
Steps:
1,) Create a folder on you C drive: C:\Data
2.) Put this code into your strategy code. Make sure you change the output file name for each market/system combo that the strategy is applied to.
if t = sessionEndtime(0,1) then begin print(file("C:\Data\Sysname-NQ.csv"),d+19000000:8:0,",",netProfit + Openpositionprofit); end;
3.) Copy and paste the following code into your favorite Python IDE or IDLE.
import tkinter as tk from tkinter import filedialog import pandas as pd import matplotlib.pyplot as plt import os
def extract_market_name(filename): """Extracts the market name from the filename formatted as 'system-market.csv'.""" return os.path.splitext(filename)[0].split('-')[-1]
def load_equity_data(files): """Loads and aligns equity data from multiple CSV files.""" data_dict = {}
def calculate_metrics(equity_curve): """Calculates total profit and maximum drawdown from the equity curve.""" total_profit = equity_curve.iloc[-1] - equity_curve.iloc[0] peak = equity_curve.cummax() drawdown = peak - equity_curve max_drawdown = drawdown.max() return total_profit, max_drawdown, drawdown
def calculate_correlation(df): """Calculates and prints the correlation matrix of equity curves.""" correlation_matrix = df.corr() print("\n--- Correlation Matrix ---") print(correlation_matrix.to_string()) print("\n--------------------------")
def plot_equity_and_drawdown(df, drawdown): """Plots the combined equity curve and drawdown as separate subplots.""" fig, ax = plt.subplots(2, 1, figsize=(12, 8), sharex=True)
4.) Run it and multi-select all the system/market .csv files
5.) Examine the results:
Combined equity, maximum draw down, and correlation matrix
How did I get ChatGPT to code this for me.
I pay $20 a month for Chat and it learns from my workflows. The more I work with it, the more it knows my end goals to the scripts I am asking it to create.
Here are the prompts I provided Chat:
I want the user to be able to use tkinter to select multiple files that contain two columns: 1-date in yyyymmdd format and 2 – the equity value for that date. The filename consists of the system name and the market name and follows the following patterm: system name”-“market name”.csv”. I need you to extract the market from the filename. If the filename is “Gatts-GC.csv”, the market name is “GC.” Once all the files are opened, I need you to align the dates and create a combined equity curve. We can do this in matplotlib if you like. I need you to calculate the total profit and the maximum drawdown among the combined equity curves.
[SCRIPT FAILED]
My data does not included headers. The first column is the date in yyyymmdd with no separators and the second column is a float value. I think your pandas are having a hard time interpreting this
[SCRIPT WORKED]
That is perfect. Can we had a correlation analysis to the equity curves and print that out too.
[SCRIPT WORKED]
Can we plot the draw down on the same canvas as the equity curves?
[SCRIPT WORKED]
Could we put the draw down in a subplot instead of in the profit plot?
[FINAL SCRIPT] Look above
Am I Worried About Being Replaced by Chat GPT?
With Python and its data visualization libraries and EasyLanguage you can overcome some of the limitations of TradeStation. And of course, ChatGPT. I have been programming in Python for nine years now and I am very good at base Python. However, Pandas are still a mystery to me and interfacing with MatPlotLib is not super simple. Does it frustrate me that I don’t know exactly what ChatGPT is coding? Yes, it did at first. But now I use it as a tool. I may not be coding the Python, but I am managing ChatGPT through my well thought out prompts and my feedback. Does my knowledge of Python help streamline this process? – I think it does. And I have trained ChatGPT during the process. I am becoming a manager-programmer and ChatGPT is my assistant.
The following is from the RealCode website – I have just copied and pasted this here. Here is the header information that provides credit to the original programmer.
Here is the description of the Indicator via ProRealCode. Please check out the website for further information regarding the indicator and how to use it.
The RMI Trend Sniper indicator is designed to identify market trends and trading signals with remarkable precision.
This tool combines the analysis of the Relative Strength Index (RSI) with the Money Flow Index (MFI) and a unique approach to range-weighted moving average to offer a comprehensive perspective on market dynamics.
Configuration and Indicator Parameters
The RMI Trend Sniper allows users to adjust various parameters according to their trading needs, including:
RMI Length: Defines the calculation period for the RMI.
Positive and Negative Momentum (Positive above / Negative below): Sets thresholds to determine the strength of bullish and bearish trends.
Range MA Visualization (Show Range MA): Enables users to visualize the range-weighted moving average, along with color indications to quickly identify the current market trend.
Cool Shading – right?
Many of my clients ask me to convert indicators from different languages. One of my clients came across this from ProRealCode and asked me to convert for his MulitCharts. Pro Real code is very similar to EasyLanguage with a few exceptions. If you are savvy in EL, then I think you could pick up PRC quite easily. Here it is. It is a trend following indicator. It is one of a few that I could not find the Easylanguage equivalent so I thought I would provide it. Play around with it and let me know what you think. Again, all credit goes to:
if positive = 1 then begin rwma = rwma-band; r=0; g=188; b=212; end else if negative = 1 then begin rwma = rwma+band; r=255; g=82; b=82; end else rwma = 0;
//------------------------------------------------------------// //-----Calculate MA bands-------------------------------------// vars: mitop(0),mibot(0);
mitop = rwma+band20; mibot = rwma-band20;
plot1(mitop,"TOP"); plot2((mitop+mibot)/2,"TOP-BOT"); plot3((mitop+mibot)/2,"BOT-TOP"); plot4(mibot,"BOT"); if positive = 1 then begin plot5(rwma,"Pos",GREEN); noPlot(plot4); end; if negative =1 then begin plot6(rwma,"Neg",RED); noPlot(plot3); end;
Ignore the RGB Color Codes
Getting Creative to Shade Between Points on the Chart
TradeStation doesn’t provide an easy method to do shading, so you have to get a little creative. The plot TOP is of type Bar High with the thickest line possible. The plot TOP-BOT (bottom of top) is of type Bar Low. I like to increase transparency as much as possible to see what lies beneath the shading . The BOT-TOP (top of bottom) is Bar High and BOT is Bar Low. Pos and Neg are of type Point. I have colored them to be GREEN or RED.
Embracing AI: The Journey from Skepticism to Synergy with ChatGPT.
Using TradeStation XML output, Python and ChatGPT to create a commercial level Portfolio Optimizer.
As a young and curious child my parents would buy me RadioShack Science Fair Kits, chemistry sets, a microscope and rockets. I learned enough chemistry to make rotten egg gas. I grew protozoa to delve into the microscopic world. I scared my mom and wowed my cousins with the Estes Der Big Red rocket. But it wasn’t until one Christmas morning I opened the Digital Computer Kit. Or course you had to put it together before you could even use it – just like the model rockets. Hey, you got an education assembling this stuff. Here is a picture of a glorified circuit board.
My first computer.
This really wasn’t a computer, but more of an education in circuit design, but you could get it to solve simple problems “Crossing the River”, decimal to binary, calculating the cube root and 97 other small projects. These problems were solved by following the various wiring diagrams. I loved how the small panels would light up with the right answers, but grew frustrated because I couldn’t get beyond the preprogrammed wiring schema. I had all these problems I wanted to solve but could not figure out the wiring. Of course, there were real computers out there such as the HAL 9000. Just kidding. I would go to the local Radio Shack and stare at the all the computers. Hoping one day I would have one sitting on my desk. My Dad was an aircraft electrician (avionics) in the U.S. Navy with a specialty in Inertial Navigation Systems. He would always want to talk about switches, gyros, some dude named Georg Ohm and oscilloscopes. I had my mind stuck in space, you know “3-D Space Battle” – the Apple II game, to listen or to learn from his vast knowledge. A couple of years later and a paper route I had a proper 16K computer, the TI-99-4A. During this time, I dreamed of a supercomputer that could answer all my questions and solve all my problems. I thought the internet was the manifestation of this dream, but in fact it was the Large Language Models such as ChatGPT.
Friend or Foe
From a programmer’s perspective AI can be scary, because you might just find yourself out of a job. From this experiment, I think we are a few years away from this possibility. Quantum computing, whenever it arrives, might be a viable replacement, but for now I think we are okay.
The Tools You Will Need
You will need a full installation of Python along with Numpy and Pandas installed on your computer if you want ChatGPT to do some serious coding for you. Python and its associated libraries are simply awesome. And Chat loves to use these tools to solve a problem. I pay $20 a month for Chat so I don’t know if you could get the same code as I did if you have the free version. You should try before signing up.
The Project: A Portfolio Optimizer using an Exhaustive Search Engine
About ten years ago, I collaborated with Mike Chalek to develop a parser that analyzes the XML files TradeStation generates when saving strategy performance data. Trading a trend-following system often requires significant capital to manage a large portfolio effectively. However, many smaller traders operate with limited resources and opt to trade a subset of the full portfolio.
This approach introduces a critical challenge: determining which markets to include in the subset to produce the most efficient equity curve. For instance, suppose you have the capital to trade only four markets out of a possible portfolio of twenty. How do you decide which four to include? Do you choose the markets with the highest individual profits? Or do you select the ones that provide the best profit-to-drawdown ratio?
For smaller traders, the latter approach—prioritizing the profit-to-drawdown ratio—is typically the smarter choice. This metric accounts for both returns and risk, making it essential for those who need to manage capital conservatively. By focusing on risk-adjusted performance, you can achieve a more stable equity curve and better protect your account from significant drawdowns.
I enhanced Mike’s parser by integrating an exhaustive search engine capable of evaluating every combination of N markets taken n at a time. This approach allowed for a complete analysis of all possible subsets within a portfolio. However, as the size of the portfolio increased, the number of combinations grew exponentially, making the computations increasingly intensive. For example, in a portfolio of 20 markets, sampling 4 markets at a time results in 4,845 unique combinations to evaluate.
Calculating the number of combinations.
Using the formula above you get 4,845 combinations. If you estimate each combination to take once second, then you are talking about 21 minutes. N/2will produce the most combinations. Sampling 10 out of 20 will take 51.32 hours.
1 out of 20: 20 combinations
2 out of 20: 190 combinations
3 out of 20: 1,140 combinations
4 out of 20: 4,845 combinations
5 out of 20: 15,504 combinations
6 out of 20: 38,760 combinations
7 out of 20: 77,520 combinations
8 out of 20: 125,970 combinations
9 out of 20: 167,960 combinations
10 out of 20: 184,756 combinations
11 out of 20: 167,960 combinations
The exhaustive method is not the best way to go when trying to find the optimal portfolios across a broad search space. This is where a genetic optimizer comes in handy. I played around with that too. However, for this experiment I stuck with a portfolio of eleven markets. I used the Andromeda-like strategy that I published in my latest installment of my Easing Into EasyLanguage series.
Here is the output of the project when sampling four markets out of a total of eleven. All this was produced with Python and its libraries and ChatGPT.
Tabular Format
The best 4-Market portfolio out of 11 possibilities.
Graphic Format
ChatGPT, Python, Matplotlib, oh my!
Step 1 – Creating an XML Parser script
You can save your strategy performance report in RINA XML format. The ability to save in this format seems to come and go, but my latest version of TradeStation provides this capability. The XML files are ASCII files that contain every bar of data, market and strategy properties and trades. However, they are extremely large as each piece of data has prefix and suffix tag.
Imagine the size of the XML when working with one or even five-minute bars.
Getting ChatGPT to create an XML parser for the specific TradeStation output
The first thing I did was save the performance, in XML format, from a workspace in TradeStation that used an Andromeda-like strategy on eleven different daily bar charts.
I asked Chat to analyze the XML file that I attached to a new chat. I started a new chart for this project. I discovered the chat session is also known as a “workflow”. This term emphasizes:
Collaboration: We work as a team to tackle challenges.
Iteration: We revisit and improve upon earlier steps as needed.
Focus: Each session builds upon the previous ones to move closer to a defined goal.
Once it understood the mapping of the XML, I asked Chat to extract the bar data and output it to a csv file. And it did it without a hitch. When I say it did it, I mean it created a Python script that I loaded into my PyScripter IDE and executed.
I then asked for an output of the trade-by-trade report, and it did it without a hitch. Notice these tasks do not require much in the way of reasoning.
Getting ChatGPT to combine the bar and trade data to produce a daily equity stream.
This is where Python and its number crunching libraries came in handy. Chat pulled in the following libraries:
xml.etree
pandas
tkinter
datetime
I love Python, but the level of abstraction with its libraries can make you dizzy. It is not important to fully understand the panda’s data frame to utilize it. Heck, I didn’t really know how it mapped and extracted the data from the XML file. I prompted chat with the following:
[My prompts are bold and italicized.]
With the bar data and the trade data and the bigpointvlaue, can you create an equity curve that shows a combination of open trade equity and closed trade equity? Remember the top part of the xml file contains bar data and the lower part contains all the trade data.
It produced a script that hung up. I informed chat that the script hung up and that the script wasn’t working. It found the error and fixed it. Think about what Chat was doing. It was able to align the data so that open trades produced open trade equity and closed out trades produced closed trade equity. Well, initially it had a small problem. It knew what Buy and Sell meant, and the math involved with calculating the two forms of equity, open and closed. I didn’t inform Chat of any of this. But the equity data did not look exactly right. It looked like the closed trade equity was being calculated improperly.
Is the Script checking for LExit and SExit to calculate when a trade closes out?
Once it figured out that the equity stream must contain open and closed trade equity and learned the terms, LExit and SExit, a new script was created that nearly replicated the equity curve from the TradeStation report. When Chat starts creating lengthy scripts it will open a side bar window call the “Canvas” and put the script in there. This makes it easier to copy and paste the code. I eventually noticed that the equity curve did not include commission and slippage charges.
Please extract the slippage and commission values and deduct this amount from each trade.
At this point the workflow remembered the mapping of the XML file and was able incorporate these two values into the trade processing. I wanted the user to be able to select multiple XML files and have the script process these files and produce the three output files, bar_data, trade_data, and equity_data. I did have to explain that the execution costs must be applied to all the entries and exits.
I would like the user to select multiple xml files and create the data and trade and equity files incorporating the system name and market name and their naming scheme.
A new library was imported, TKinter and a file open dialog was used for the user to select all the XML files they wanted to process. These few chores required very little interaction between Chat and me. I thought, wow this is going to be a breeze. I moved onto the next phase of the project by asking Chat the following:
Can you create a script that will use Tkinter to open the equity files from the prior script and allow the user to choose N out of the total files selected to create all the combined equity curves using an exhaustive search method.
I knew this was a BIG ASK! But it swallowed this big pill without a hitch. Maybe us programmers will be replaced sooner than later. I wanted to fine tune the script.
Can you keep track of maximum draw down for each combination and then sort the combinations by the profit to draw down ratio. For the best combination can you create a csv file with the daily returns so i can plot them in Excel.
On a quick scan of the results, I did not initially notice that the maximum draw-down metric was not right. So, I pushed on the fine tuning.
This works great. In the output files can we delete the path name to the csv files. For the output I would just like to have the system name and the symbol for each combination.
Script created.
I had the following error message. NameError: name ‘all_combinations’ is not defined. I also asked Chat if it can you add “Date” to the header for the combination daily files?
Many times, Chat will just recreate the part of the code that needs to be modified. This makes copying and pasting difficult, because you have to make sure you find the right location in the code to replace. I always ask Chat to recreate the entire script with the latest changes.
Hey Chat, the following error message was created: system, symbol = filename.replace(“.csv”, “”).split(“_”) ValueError: too many values to unpack (expected 2)
The error was fixed, but I finally noticed the maximum draw down calculations were not right.
I don’t think the maximum draw down metric is being calculated properly. “Andromeda-Like_@SB, Andromeda-Like_@EC, Andromeda-Like_@S, Andromeda-Like_@JY”,
PL: 92141.8499999999,
DD: 92985.59999999992,
Ratio: 0.990926014350609,144.
The draw down metric is similar to the total profit metric.
Script created.
The draw down is still not calculated properly. I think there is an error in your reasoning. I calculate draw down by iterating through the equity curve and keeping track of peaks and subsequent troughs. The largest distance between the peaks and its associated trough is the max draw down.
Script created but looked a little primitive. So, I asked.
Is this the most efficient method?
Well, I should have kept my mouth shut. I felt like the Python libraries would be able to do this much quicker with list comprehension or with some other magic. And Chat agreed with me. Script created.
The draw down is still incorrect.
Script created.
It was still wrong and instead of going back and using the original draw down script I tried to nudge Chat into the right direction.
The equity curve will have multiple peaks and multiple troughs. You will need to keep track of all of the peaks and troughs and then find the maximum distance between the sets of peaks and troughs.
Script created and was still wrong. This is where you start going down a rabbit hole. Chat will produce debugging script to try and figure out where the error resides. But this is very time consuming, so I kept pushing Chat to do it right.
Each peak must be tied to its respective trough. Each distance between each respective peak and drawdown can then be measured for the largest value.
Script is wrong.
This still not working. I don’t think you are calculating the difference between peaks and subsequent troughs properly.
Script is wrong.
This is still not working. We should be able to do this in a single pass. Iterate through the daily values and track the highest level at that point in the series and then the subsequent deepest trough. Store the first difference. Continue iterating looking for a new peak and the subsequent deepest trough. Compare this value to the prior and take the largest of the two. Store this value and continue iterating.
Script from original request is generated. Finally got back to the starting point. What a waste of time. I will be more careful with my suggestions. However, the script is still wrong – arrgh! I decide to run the debugger on the draw down function and the code is right, but the data is wrong.
The problem lies in the equity series. It should contain the combined equity for the combinations. There should be a master date and each combination populates the master date. If there is a missing date in the combinations, then the master date should copy the prior combinations combined value.
Warning message: se obj.ffill() or obj.bfill() instead. df_aligned = df.reindex(master_date_index).fillna(method=”ffill”).fillna(0)
Chat created some deprecated code. This was an easy fix, I just had to replace one line of code. However, every iteration following this still had the same damn deprecated code.
Error or warning: FutureWarning: Series.getitem treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use ser.iloc[pos] peak = equity_series[0] # Initialize the first value as the peak
Script updated.
Can we drop the “_equity_curve” from the name of the system and symbol in the Perfomance metrics file. Will excel accept the combination names as a single column or will each symbol have its own column because of the comma. I would like for each combination in the Performance_Metrics file to occupy just one column.
Script created and this is what it should look like. Notice it was remembering the wrong maximum draw down values I fed it earlier. Don’t worry it was right in the script.
Combination
Total Profit
Max Drawdown
Profit-to-Drawdown Ratio
Combination Number
“Andromeda-Like_@SB, Andromeda-Like_@EC”
92141.85
92985.60
0.99
1
“Andromeda-Like_@S, Andromeda-Like_@JY”
82450.55
70530.45
1.17
2
Conclusion
I could have done the same thing ChatGPT did for me, but I wouldn’t have used the Numpy or Pandas libraries simply because I’m not familiar with them. These libraries make the exhaustive search manageable and incredibly efficient. They handle tasks much faster than pure Python alone.
To get ChatGPT to generate the code you need, being a programmer is essential. You’ll need to guide it through debugging, steer it in the right direction, and test the scripts it produces. It’s a back-and-forth process—running the script, identifying warnings or errors, and pointing out incorrect outputs. Sometimes, your programming insights and suggestions might inadvertently lead ChatGPT down a rabbit hole. Features that worked in earlier versions may stop working in subsequent iterations as modifications are applied to address earlier issues.
ChatGPT can also slow down at times, and its Canvas tool has a line limit, which can result in incomplete scripts. As a programmer, it’s easy to spot these issues—you’ll need to inform ChatGPT, and it will adjust by splitting the script into parts, some appearing in the Canvas and the rest in the chat window.
The collaboration between ChatGPT and me was powerful enough to replicate, in just one day, software that Mike Chalek and I spent weeks developing a decade ago. The original version had a cleaner GUI, but it was significantly slower compared to what we’ve achieved here.
If you’re a programmer, have Python installed with its libraries, and work with ChatGPT, the possibilities are endless. But there’s no magic—success requires thoughtful feedback and precise prompting.
Email me if you would like to have the Python scripts that accomplish the following tasks. If you are not familiar with pandas or xml processing, the code, even being Python savvy, will look a little foreign. No worries – it just works.
XML Parser – creates data, trades and equity files in .csv format.
TradeStationExhaustiveCombos – creates all the combos when sampling n out of N markets.
The simple Tkinter GUI and Matplotlib graphing tool to plot the combos.
There is a total of three scripts. Remember you will need to have Python, pandas, matplotlib already installed on your computer. If you have any questions on how to install these just let me know.
Backtesting with [Trade Station,Python,AmiBroker, Excel]. Intended for informational and educational purposes only!
Get All Five Books in the Easing Into EasyLanguage Series - The Trend Following Edition is now Available!
Announcement – A Trend Following edition has been added to my Easing into EasyLanguage Series! This edition will be the fifth and final installment and will utilize concepts discussed in the Foundation editions. I will pay respect to the legends of Trend Following by replicating the essence of their algorithms. Learn about the most prominent form of algorithmic trading. But get geared up for it by reading the first four editions in the series now. Get your favorite QUANT the books they need!
The Foundation Edition. The first in the series.
This series includes five editions that covers the full spectrum of the EasyLanguage programming language. Fully compliant with TradeStation and mostly compliant with MultiCharts. Start out with the Foundation Edition. It is designed for the new user of EasyLanguage or for those you would like to have a refresher course. There are 13 tutorials ranging from creating Strategies to PaintBars. Learn how to create your own functions or apply stops and profit objectives. Ever wanted to know how to find an inside day that is also a Narrow Range 7 (NR7?) Now you can, and the best part is you get over 4 HOURS OF VIDEO INSTRUCTION – one for each tutorial.
Hi-Res Edition Cover
This book is ideal for those who have completed the Foundation Edition or have some experience with EasyLanguage, especially if you’re ready to take your programming skills to the next level. The Hi-Res Edition is designed for programmers who want to build intraday trading systems, incorporating trade management techniques like profit targets and stop losses. This edition bridges the gap between daily and intraday bar programming, making it easier to handle challenges like tracking the sequence of high and low prices within the trading day. Plus, enjoy 5 hours of video instruction to guide you through each tutorial.
Advanced Topics Cover
The Advanced Topics Edition delves into essential programming concepts within EasyLanguage, offering a focused approach to complex topics. This book covers arrays and fixed-length buffers, including methods for element management, extraction, and sorting. Explore finite state machines using the switch-case construct, text graphic manipulation to retrieve precise X and Y coordinates, and gain insights into seasonality with the Ruggiero/Barna Universal Seasonal and Sheldon Knight Seasonal methods. Additionally, learn to build EasyLanguage projects, integrate fundamental data like Commitment of Traders, and create multi-timeframe indicators for comprehensive analysis.
Get Day Trading Edition Today!
The Day Trading Edition complements the other books in the series, diving into the popular approach of day trading, where overnight risk is avoided (though daytime risk still applies!). Programming on high-resolution data, such as five- or one-minute bars, can be challenging, and this book provides guidance without claiming to be a “Holy Grail.” It’s not for ultra-high-frequency trading but rather for those interested in techniques like volatility-based breakouts, pyramiding, scaling out, and zone-based trading. Ideal for readers of the Foundation and Hi-Res editions or those with EasyLanguage experience, this book offers insights into algorithms that shaped the day trading industry.
Trend Following Cover.
For thirty-one years as the Director of Research at Futures Truth Magazine, I had the privilege of collaborating with renowned experts in technical analysis, including Fitschen, Stuckey, Ruggiero, Fox, and Waite. I gained invaluable insights as I watched their trend-following methods reach impressive peaks, face sharp declines, and ultimately rebound. From late 2014 to early 2020, I witnessed a dramatic downturn across the trend-following industry. Iconic systems like Aberration, CatScan, Andromeda, and Super Turtle—once thriving on robust trends of the 1990s through early 2010s—began to falter long before the pandemic. Since 2020 we have seen the familiar trends return. Get six hours of video instruction with this edition.
Pick up your copies today – e-Book or paperback format – at Amazon.com